Publications
Group highlights
At the end of this page, you can find the full list of publications and patents.
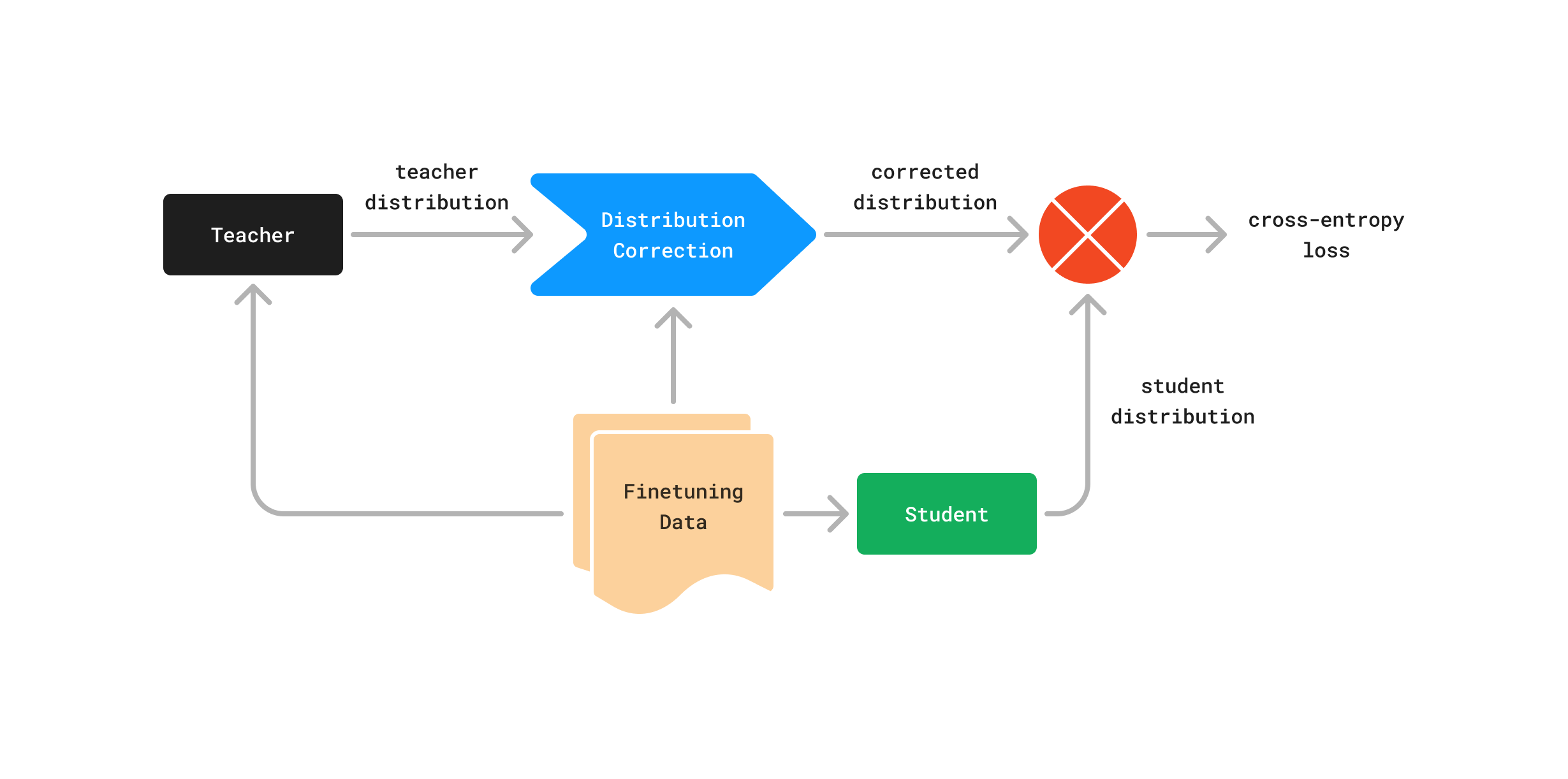
Finetuning language models for a new domain inevitably leads to the deterioration of their general performance. This becomes more pronounced the more limited the finetuning data resource.We introduce minifinetuning (MFT), a method for language model domain adaptation that considerably reduces the effects of overfitting-induced degeneralization in low-data settings and which does so in the absence of any pre-training data for replay. MFT demonstrates 2-10x more favourable specialization-to-degeneralization ratios than standard finetuning across a wide range of models and domains and exhibits an intrinsic robustness to overfitting when data in the new domain is scarce and down to as little as 500 samples.Employing corrective self-distillation that is individualized on the sample level, MFT outperforms parameter-efficient finetuning methods, demonstrates replay-like degeneralization mitigation properties, and is composable with either for a combined effect.
Peter Belcak, Greg Heinrich, Jan Kautz, Pavlo Molchanov
| Arxiv || Project Page |

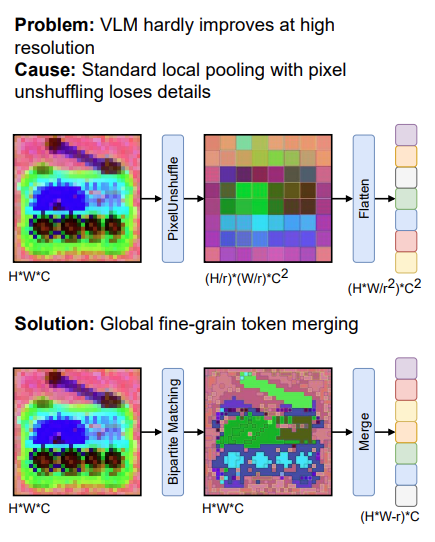
The feature maps of vision encoders are fundamental to myriad modern AI tasks, ranging from core perception algorithms (e.g. semantic segmentation, object detection, depth perception, etc.) to modern multimodal understanding in vision-language models (VLMs). Currently, in computer vision, the frontier of general purpose vision backbones are Vision Transformers (ViT), typically trained using contrastive loss (e.g. CLIP). A key problem with most off-the-shelf ViTs, particularly CLIP, is that these models are inflexibly low resolution. Most run at 224x224px, while the “high resolution” versions are around 378-448px, but still inflexible. We introduce a novel method to coherently and cheaply upsample the feature maps of low-res vision encoders while picking up on fine-grained details that would otherwise be lost due to resolution. We demonstrate the effectiveness of this approach on core perception tasks as well as within agglomerative model (RADIO) training as a way of providing richer targets for distillation.
Mike Ranzinger, Greg Heinrich, Pavlo Molchanov, Jan Kautz, Bryan Catanzaro, Andrew Tao
Presented at ICML 2025
| Arxiv |
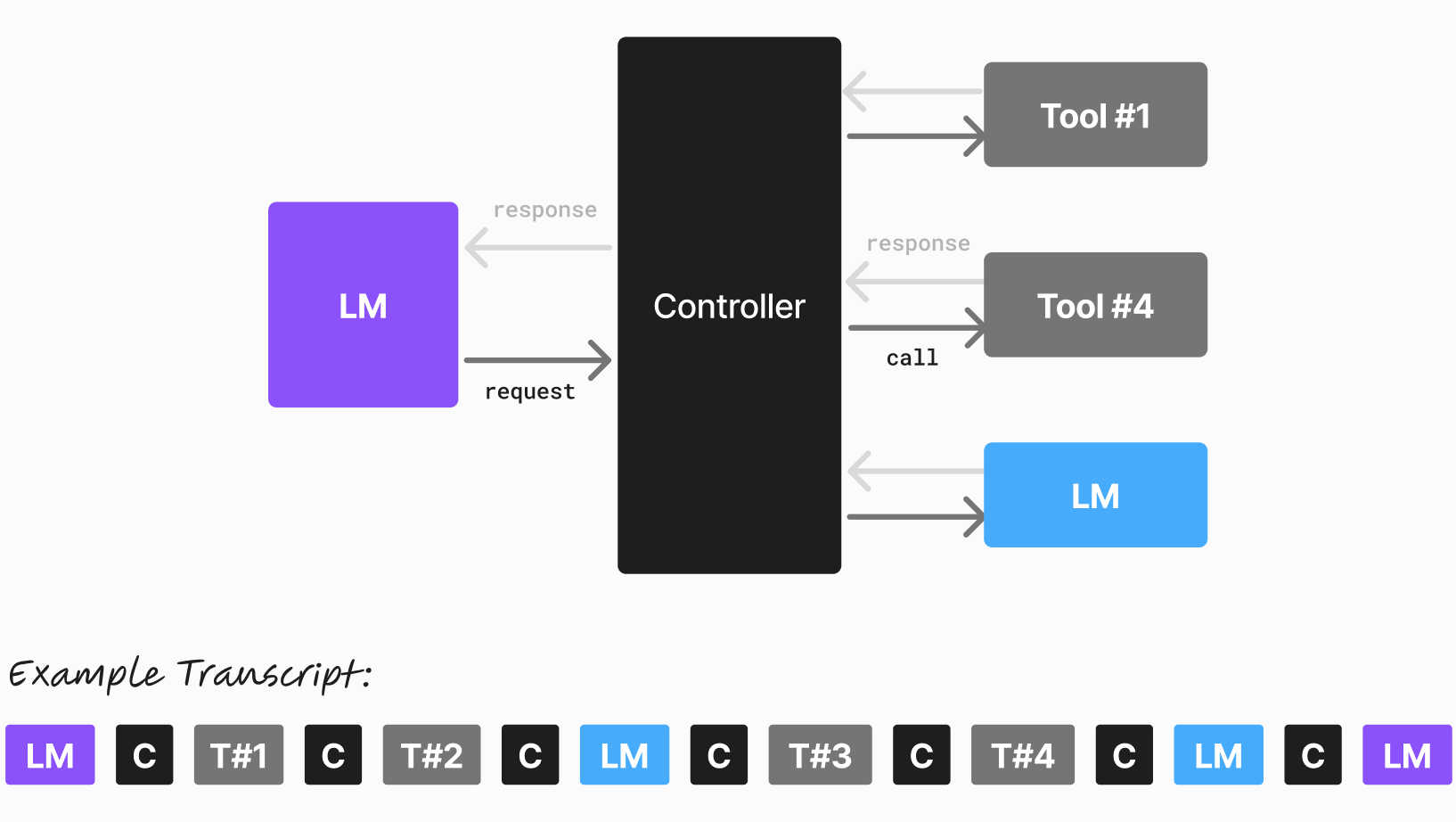
Small language models (SLMs) are often overlooked in favor of larger, more powerful models. However, we argue that small LLMs are the future of agentic AI due to their efficiency, accessibility, and adaptability. Here we detail our position on the future of agentic AI, arguing with evidence that that the industry and the community are to benefit from a switch from LLMs to SLMs. Our position is based on three key points: That SLMs are sufficiently powerful, inherently more suitable, and necessarily more economical for many invocations in agentic systems. We then draw a conclusion that they are, to a large extent, the future of agentic AI. We also outline a LLM-to-SLM conversion algorithm that can be employed to produce a SLM for a specific agentic workflow. We welcome correspondence on the topic.
Peter Belcak, Greg Heinrich, Shizhe Diao, Yonggan Fu, Xin Dong, Saurav Muralidharan, Yingyan Celine Lin, Pavlo Molchanov
| Arxiv || Project/Correspondence Page |

We introduce NVILA, a family of open visual language models (VLMs) designed to optimize both efficiency and accuracy. Building upon VILA, NVILA employs a ‘scale-then-compress’ strategy—first enhancing spatial and temporal resolutions to preserve visual details, then compressing visual tokens to reduce computational overhead. This approach enables NVILA to efficiently process high-resolution images and long videos. Our systematic investigation enhances NVILA’s efficiency throughout its lifecycle, from training and fine-tuning to deployment. NVILA matches or surpasses the accuracy of many leading open and proprietary VLMs across a wide range of image and video benchmarks. Simultaneously, it reduces training costs by 4.5×, fine-tuning memory usage by 3.4×, pre-filling latency by 1.6–2.2×, and decoding latency by 1.2–2.8×.
Zhijian Liu, Ligeng Zhu, Baifeng Shi, Zhuoyang Zhang, Yuming Lou, Shang Yang, Haocheng Xi, Shiyi Cao, Yuxian Gu, Dacheng Li, Xiuyu Li, Yunhao Fang, Yukang Chen, Cheng-Yu Hsieh, De-An Huang, An-Chieh Cheng, Vishwesh Nath, Jinyi Hu, Sifei Liu, Ranjay Krishna, Daguang Xu, Xiaolong Wang, Pavlo Molchanov, Jan Kautz, Hongxu Yin, Song Han, Yao Lu
| Arxiv || Project Page || GitHub |

We introduce PS3, a framework that scales CLIP-style vision pre-training to 4K resolution with near-constant cost by selectively processing local regions and contrasting them with detailed captions. This enables high-resolution representation learning with greatly reduced computational overhead. The resulting model, VILA-HD, significantly improves high-resolution visual perception compared to baselines without high-resolution vision pre-training, such as AnyRes and S², while using up to 4.3× fewer tokens. VILA-HD outperforms previous multi-modal large language models (MLLMs), including NVILA and Qwen2-VL, across multiple benchmarks. To further evaluate high-resolution perception, we propose 4KPro, a new benchmark of image QA at 4K resolution, on which VILA-HD achieves a 14.5% improvement over GPT-4o and a 3.2% improvement with 2.96× speedup over Qwen2-VL.
Baifeng Shi, Boyi Li, Han Cai, Yao Lu, Sifei Liu, Marco Pavone, Jan Kautz, Song Han, Trevor Darrell, Pavlo Molchanov, Hongxu Yin
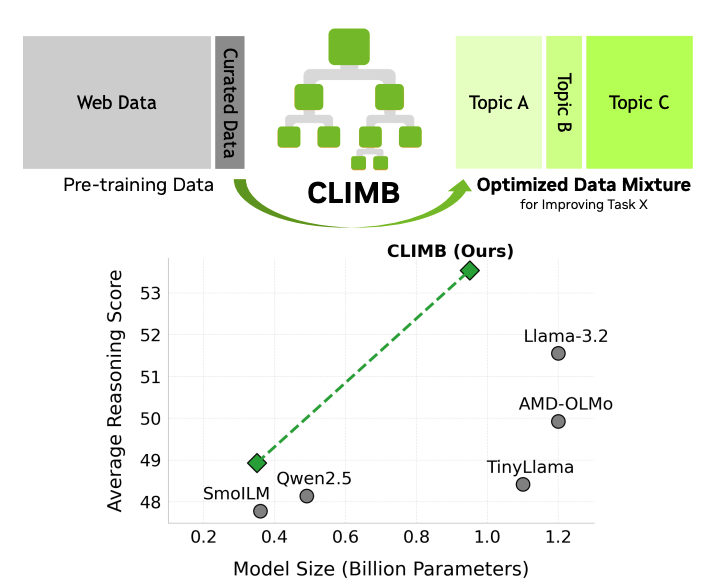
We introduce CLustering-based Iterative Data Mixture Bootstrapping (CLIMB), an automated framework that discovers, evaluates, and refines data mixtures in a pre-training setting. Specifically, CLIMB embeds and clusters large-scale datasets in a semantic space and then iteratively searches for optimal mixtures using a smaller proxy model and a predictor. When continuously trained on 400B tokens with this mixture, our 950M model exceeds the state-of-the-art Llama-3.2-1B by 2.0% averaged across 12 general reasoning tasks. Moreover, we observe that optimizing for a specific domain (e.g., Social Sciences) yields a 5% improvement over random sampling. We introduce ClimbLab, a filtered 1.3-trillion-token corpus with 20 clusters as a research playground, and ClimbMix, a compact yet powerful 400-billion-token dataset designed for efficient pre-training that delivers superior performance under an equal token budget.
Shizhe Diao, Yu Yang, Yonggan Fu, Xin Dong, Dan Su, Markus Kliegl, Zijia Chen, Peter Belcak, Yoshi Suhara, Hongxu Yin, Mostofa Patwary, Yingyan (Celine) Lin, Jan Kautz, Pavlo Molchanov
| Arxiv || HF datasets || Homepage |
Agglomerative models have recently emerged as a powerful approach to training vision foundation models, leveraging multi-teacher distillation from existing models such as CLIP, DINO, and SAM. This strategy enables the efficient creation of robust models, combining the strengths of individual teachers while significantly reducing computational and resource demands. In this paper, we thoroughly analyze state-of-the-art agglomerative models, identifying critical challenges including resolution mode shifts, teacher imbalance, idiosyncratic teacher artifacts, and an excessive number of output tokens. To address these issues, we propose several novel solutions: multi-resolution training, mosaic augmentation, and improved balancing of teacher loss functions. Specifically, in the context of Vision Language Models, we introduce a token compression technique to maintain high-resolution information within a fixed token count.
Greg Heinrich, Mike Ranzinger, Hongxu (Danny)Yin, Yao Lu, Jan Kautz, Andrew Tao, Bryan Catanzaro, Pavlo Molchanov
Presented at CVPR 2025
| Arxiv |
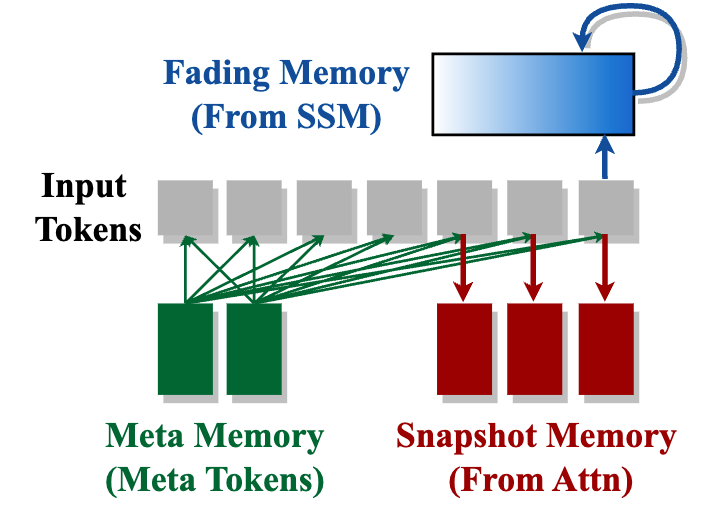
We propose Hymba, a family of small language models featuring a hybrid-head parallel architecture that integrates transformer attention mechanisms with state space models (SSMs) for enhanced efficiency. Attention heads provide high-resolution recall, while SSM heads enable efficient context summarization. Additionally, we introduce learnable meta tokens that are prepended to prompts, storing critical information and alleviating the “forced-to-attend” burden associated with attention mechanisms. This model is further optimized by incorporating cross-layer key-value (KV) sharing and partial sliding window attention, resulting in a compact cache size. Notably, Hymba achieves state-of-the-art results for small LMs.
Xin Dong, Yonggan Fu, Shizhe Diao, Wonmin Byeon, Zijia Chen, Ameya Sunil Mahabaleshwarkar, Shih-Yang Liu, Matthijs Van Keirsbilck, Min-Hung Chen, Yoshi Suhara, Yingyan Lin, Jan Kautz, Pavlo Molchanov
Presented at ICLR 2025 (spotlight)
| Arxiv || HF models || Blog |

We develop an efficient model compression strategy for LLMs that combines depth, width, attention and MLP pruning with knowledge-distillation-based retraining. We use our strategy to compress the Nemotron-4 family of LLMs by a factor of 2-4x, and compare their performance to similarly-sized models on a variety of language modeling tasks. Deriving 8B and 4B models from an already pretrained 15B model using our approach requires up to 40x fewer training tokens per model compared to training from scratch; this results in compute cost savings of 1.8x for training the full model family (15B, 8B, and 4B).
Saurav Muralidharan, Sharath Turuvekere Sreenivas, Raviraj Joshi, Marcin Chochowski, Mostofa Patwary, Mohammad Shoeybi, Bryan Catanzaro, Jan Kautz, Pavlo Molchanov
| Arxiv || HF models || Blog |
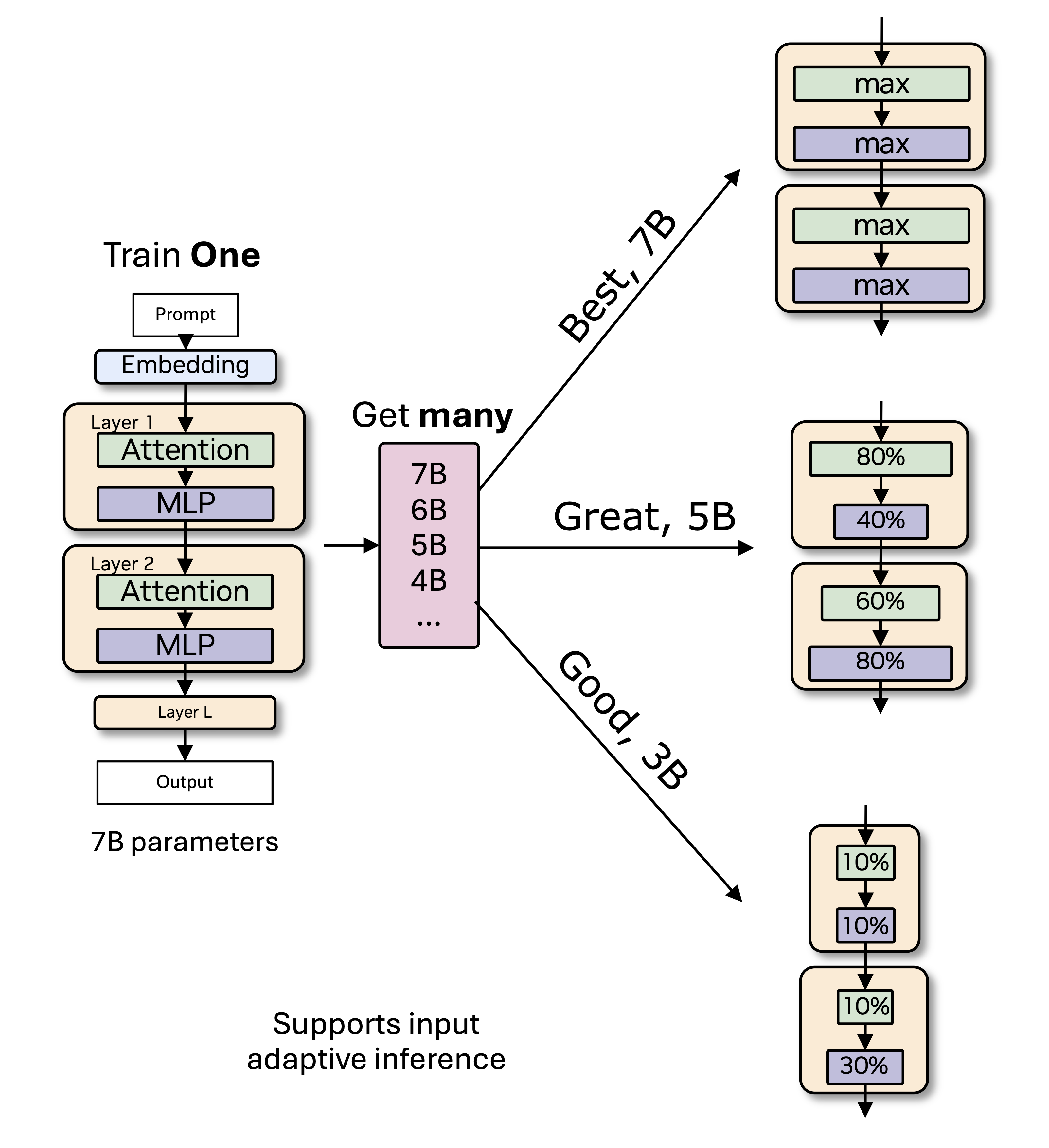
Training modern LLMs is extremely resource intensive, and customizing them for various deployment scenarios characterized by limited compute and memory resources through repeated training is impractical. We introduce Flextron, a network architecture and post-training model optimization framework supporting flexible model deployment.
Ruisi Cai, Saurav Muralidharan, Greg Heinrich, Hongxu Yin, Zhangyang Wang, Jan Kautz, Pavlo Molchanov
Presented at ICML 2024 (oral)
Full List of publications
Minifinetuning: Low-Data Generation Domain Adaptation through Corrective Self-Distillation
Peter Belcak, Greg Heinrich, Jan Kautz, Pavlo Molchanov
| Arxiv || Project Page |
FeatSharp: Your Vision Model Features, Sharper
Mike Ranzinger, Greg Heinrich, Pavlo Molchanov, Jan Kautz, Bryan Catanzaro, Andrew Tao
| Arxiv |
Small Language Models are the Future of Agentic AI
Peter Belcak, Greg Heinrich, Shizhe Diao, Yonggan Fu, Xin Dong, Saurav Muralidharan, Yingyan Celine Lin, Pavlo Molchanov
| Arxiv || Project/Correspondence Page |
VILA-M3: Enhancing Vision-Language Models with Medical Expert Knowledge
Vishwesh Nath, Wenqi Li, Dong Yang, Andriy Myronenko, Mingxin Zheng, Yao Lu, Zhijian Liu, Hongxu Yin, Yee Man Law, Yucheng Tang, Pengfei Guo, Can Zhao, Ziyue Xu, Yufan He, Greg Heinrich, Stephen Aylward, Marc Edgar, Michael Zephyr, Pavlo Molchanov, Baris Turkbey, Holger Roth, Daguang Xu
| Arxiv || GitHub || Hugging Face Model |
NaVILA: Legged Robot Vision-Language-Action Model for Navigation
An-Chieh Cheng, Yandong Ji, Zhaojing Yang, Zaitian Gongye, Xueyan Zou, Jan Kautz, Erdem Bıyık, Hongxu Yin, Sifei Liu, Xiaolong Wang
| Arxiv || Project Page |
NVILA: Efficient Frontier Visual Language Models
Zhijian Liu, Ligeng Zhu, Baifeng Shi, Zhuoyang Zhang, Yuming Lou, Shang Yang, Haocheng Xi, Shiyi Cao, Yuxian Gu, Dacheng Li, Xiuyu Li, Yunhao Fang, Yukang Chen, Cheng-Yu Hsieh, De-An Huang, An-Chieh Cheng, Vishwesh Nath, Jinyi Hu, Sifei Liu, Ranjay Krishna, Daguang Xu, Xiaolong Wang, Pavlo Molchanov, Jan Kautz, Hongxu Yin, Song Han, Yao Lu
| Arxiv || Project Page || GitHub |
VILA-HD: Scaling Vision Pre-Training to 4K Resolution
Baifeng Shi, Boyi Li, Han Cai, Yao Lu, Sifei Liu, Marco Pavone, Jan Kautz, Song Han, Trevor Darrell, Pavlo Molchanov, Hongxu Yin
| Arxiv || PubPage |
CLIMB: CLustering-based Iterative Data Mixture Bootstrapping
Shizhe Diao, Yu Yang, Yonggan Fu, Xin Dong, Dan Su, Markus Kliegl, Zijia Chen, Peter Belcak, Yoshi Suhara, Hongxu Yin, Mostofa Patwary, Yingyan (Celine) Lin, Jan Kautz, Pavlo Molchanov
| Arxiv || HF datasets || Homepage |
PHI-S: Distribution Balancing for Label-Free Multi-Teacher Distillation
Mike Ranzinger, Jon Barker, Greg Heinrich, Pavlo Molchanov, Bryan Catanzaro, Andrew Tao
| Arxiv |
RADIOv2.5: Improved Baselines for Agglomerative Vision Foundation Models
Greg Heinrich, Mike Ranzinger, Hongxu (Danny)Yin, Yao Lu, Jan Kautz, Andrew Tao, Bryan Catanzaro, Pavlo Molchanov
| Arxiv |
Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
Aaron Blakeman, Aarti Basant, Abhinav Khattar, Adithya Renduchintala, Akhiad Bercovich, Aleksander Ficek, Alexis Bjorlin, Ali Taghibakhshi, Amala Sanjay Deshmukh, Ameya Sunil Mahabaleshwarkar, Andrew Tao, Anna Shors, Ashwath Aithal, Ashwin Poojary, Ayush Dattagupta, Balaram Buddharaju, Bobby Chen, Boris Ginsburg, Boxin Wang, Brandon Norick, Brian Butterfield, Bryan Catanzaro, Carlo del Mundo, Chengyu Dong, Christine Harvey, Christopher Parisien, Dan Su, Daniel Korzekwa, Danny Yin, Daria Gitman, David Mosallanezhad, Deepak Narayanan, Denys Fridman, Dima Rekesh, Ding Ma, Dmytro Pykhtar, Dong Ahn, Duncan Riach, Dusan Stosic, Eileen Long, Elad Segal, Ellie Evans, Eric Chung, Erick Galinkin, Evelina Bakhturina, Ewa Dobrowolska, Fei Jia, Fuxiao Liu, Gargi Prasad, Gerald Shen, Guilin Liu, Guo Chen, Haifeng Qian, Helen Ngo, Hongbin Liu, Hui Li, Igor Gitman, Ilia Karmanov, Ivan Moshkov, Izik Golan, Jan Kautz, Jane Polak Scowcroft, Jared Casper, Jarno Seppanen, Jason Lu, Jason Sewall, Jiaqi Zeng, Jiaxuan You, Jimmy Zhang, Jing Zhang, Jining Huang, Jinze Xue, Jocelyn Huang, Joey Conway, John Kamalu, Jon Barker, Jonathan Cohen, Joseph Jennings, Jupinder Parmar, Karan Sapra, Kari Briski, Kateryna Chumachenko, Katherine Luna, Keshav Santhanam, Kezhi Kong, Kirthi Sivamani, Krzysztof Pawelec, Kumar Anik, Kunlun Li, Lawrence McAfee, Leon Derczynski, Lindsey Pavao, Luis Vega, Lukas Voegtle, Maciej Bala, Maer Rodrigues de Melo, Makesh Narsimhan Sreedhar, Marcin Chochowski, Markus Kliegl et al.
| Arxiv |
EoRA: Training-free Compensation for Compressed LLM with Eigenspace Low-Rank Approximation
Shih-Yang Liu, Maksim Khadkevich, Nai Chit Fung, Charbel Sakr, Chao-Han Huck Yang, Chien-Yi Wang, Saurav Muralidharan, Hongxu Yin, Kwang-Ting Cheng, Jan Kautz, Yu-Chiang Frank Wang, Pavlo Molchanov, Min-Hung Chen
| Arxiv |
MaskLLM: Learnable Semi-Structured Sparsity for Large Language Models
Gongfan Fang, Hongxu Yin, Saurav Muralidharan, Greg Heinrich, Jeff Pool, Jan Kautz, Pavlo Molchanov, Xinchao Wang
| Arxiv |
Efficient Hybrid Language Model Compression through Group-Aware SSM Pruning
Ali Taghibakhshi, Sharath Turuvekere Sreenivas, Saurav Muralidharan, Marcin Chochowski, Yashaswi Karnati, Raviraj Joshi, Ameya Sunil Mahabaleshwarkar, Zijia Chen, Yoshi Suhara, Oluwatobi Olabiyi, Daniel Korzekwa, Mostofa Patwary, Mohammad Shoeybi, Jan Kautz, Bryan Catanzaro, Ashwath Aithal, Nima Tajbakhsh, Pavlo Molchanov
| Arxiv |
LLM Pruning and Distillation in Practice: The Minitron Approach
Sharath Turuvekere Sreenivas, Saurav Muralidharan, Raviraj Joshi, Marcin Chochowski, Ameya Sunil Mahabaleshwarkar, Gerald Shen, Jiaqi Zeng, Zijia Chen, Yoshi Suhara, Shizhe Diao, Chenhan Yu, Wei-Chun Chen, Hayley Ross, Oluwatobi Olabiyi, Ashwath Aithal, Oleksii Kuchaiev, Daniel Korzekwa, Pavlo Molchanov, Mostofa Patwary, Mohammad Shoeybi, Jan Kautz, Bryan Catanzaro
| Arxiv |
LLaMaFlex: Many-in-one LLMs via Generalized Pruning and Weight Sharing
Ruisi Cai, Saurav Muralidharan, Hongxu Yin, Zhangyang Wang, Jan Kautz, Pavlo Molchanov
| OpenReview |
LongMamba: Enhancing Mamba’s Long Context Capabilities via Training-Free Receptive Field Enlargement
Zhifan Ye, Kejing Xia, Yonggan Fu, Xin Dong, Jihoon Hong, Xiangchi Yuan, Shizhe Diao, Jan Kautz, Pavlo Molchanov, Yingyan Celine Lin
| Arxiv |
Hymba: A Hybrid-head Architecture for Small Language Models
Xin Dong, Yonggan Fu, Shizhe Diao, Wonmin Byeon, Zijia Chen, Ameya Sunil Mahabaleshwarkar, Shih-Yang Liu, Matthijs Van Keirsbilck, Min-Hung Chen, Yoshi Suhara, Yingyan Lin, Jan Kautz, Pavlo Molchanov
| Arxiv || HF models || Blog |
Compact Language Models via Pruning and Knowledge Distillation
Saurav Muralidharan, Sharath Turuvekere Sreenivas, Raviraj Joshi, Marcin Chochowski, Mostofa Patwary, Mohammad Shoeybi, Bryan Catanzaro, Jan Kautz, Pavlo Molchanov
| Arxiv || HF models || Blog |
DoRA: Weight-Decomposed Low-Rank Adaptation
Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, Min-Hung Chen
| Arxiv || Code |
AM-RADIO: Agglomerative Vision Foundation Model Reduce All Domains Into One
Mike Ranzinger, Greg Heinrich, Jan Kautz, Pavlo Molchanov.
| Arxiv || GitHub || HF models |
VILA: Cross-Modality Alignment for Large Language Model
Ji Lin, Hongxu Yin, Wei Ping, Yao Lu, Pavlo Molchanov, Andrew Tao, Huizi Mao, Jan Kautz, Mohammad Shoeybi, Song Han
| Arxiv || Code || Blog || Tutorial |
A Deeper Look at Depth Pruning of LLMs
Shoaib Ahmed Siddiqui, Xin Dong, Greg Heinrich, Thomas Breuel, Jan Kautz, David Krueger, Pavlo Molchanov
| Arxiv |
Flextron: Many-in-One Flexible Large Language Model
Ruisi Cai, Saurav Muralidharan, Greg Heinrich, Hongxu Yin, Zhangyang Wang, Jan Kautz, Pavlo Molchanov
| Arxiv || Webpage |
Step Out and Seek Around: On Warm-Start Training with Incremental Data
Maying Shen, Hongxu Yin, Pavlo Molchanov, Lei Mao, Jose M. Alvarez
| Arxiv |
X-VILA: Cross-Modality Alignment for Large Language Model
Hanrong Ye, De-An Huang, Yao Lu, Zhiding Yu, Wei Ping, Andrew Tao, Jan Kautz, Song Han, Dan Xu, Pavlo Molchanov, Hongxu Yin
| Arxiv |
VILA2: VILA Augmented VILA
Yunhao Fang, Ligeng Zhu, Yao Lu, Yan Wang, Pavlo Molchanov, Jang Hyun Cho, Marco Pavone, Song Han, Hongxu Yin
| Arxiv |
SpatialRGPT: Grounded Spatial Reasoning in Vision Language Model
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xiaolong Wang, Sifei Liu
| Arxiv |
RegionGPT: Towards Region Understanding Vision Language Model
Qiushan Guo, Shalini De Mello, Hongxu Yin, Wonmin Byeon, Ka Chun Cheung, Yizhou Yu, Ping Luo, Sifei Liu
| Arxiv |